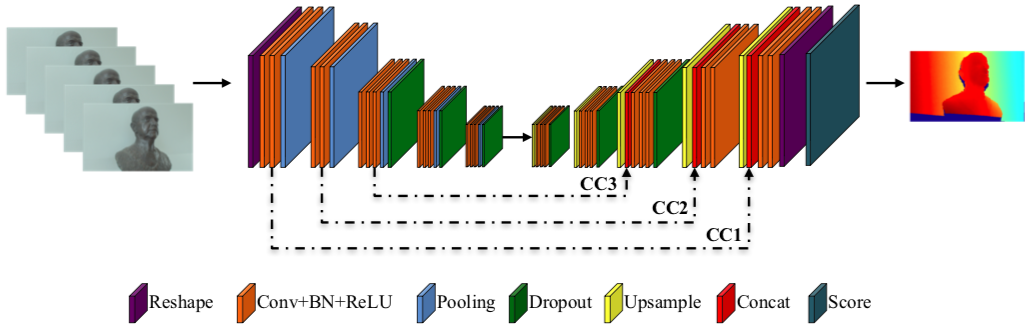
Depth from focus (DFF) is one of the classical ill-posed inverse problems in computer vision. Most approaches recover the depth at each pixel based on the focal setting which exhibits maximal sharpness. Yet, it is not obvious how to reliably estimate the sharpness level, particularly in low-textured areas. In this paper, we propose `Deep Depth From Focus (DDFF)' as the first end-to-end learning approach to this problem. One of the main challenges we face is the hunger for data of deep neural networks. In order to obtain a significant amount of focal stacks with corresponding groundtruth depth, we propose to leverage a light-field camera with a co-calibrated RGB-D sensor. This allows us to digitally create focal stacks of varying sizes. Compared to existing benchmarks our dataset is 25 times larger, enabling the use of machine learning for this inverse problem. We compare our results with state-of-the-art DFF methods and we also analyze the effect of several key deep architectural components. These experiments show that our proposed method `DDFFNet' achieves state-of-the-art performance in all scenes, reducing depth error by more than 75% wrt classic DFF methods.
Bibtex
@InProceedings{hazirbas18ddff,
author = {C. Hazirbas and S. G. Soyer and M. C. Staab and L. Leal-Taixé and D. Cremers},
title = {Deep Depth From Focus},
booktitle = {Asian Conference on Computer Vision (ACCV)},
year = {2018},
month = {December},
eprint = {1704.01085},
url = {https://hazirbas.com/projects/ddff/},
}