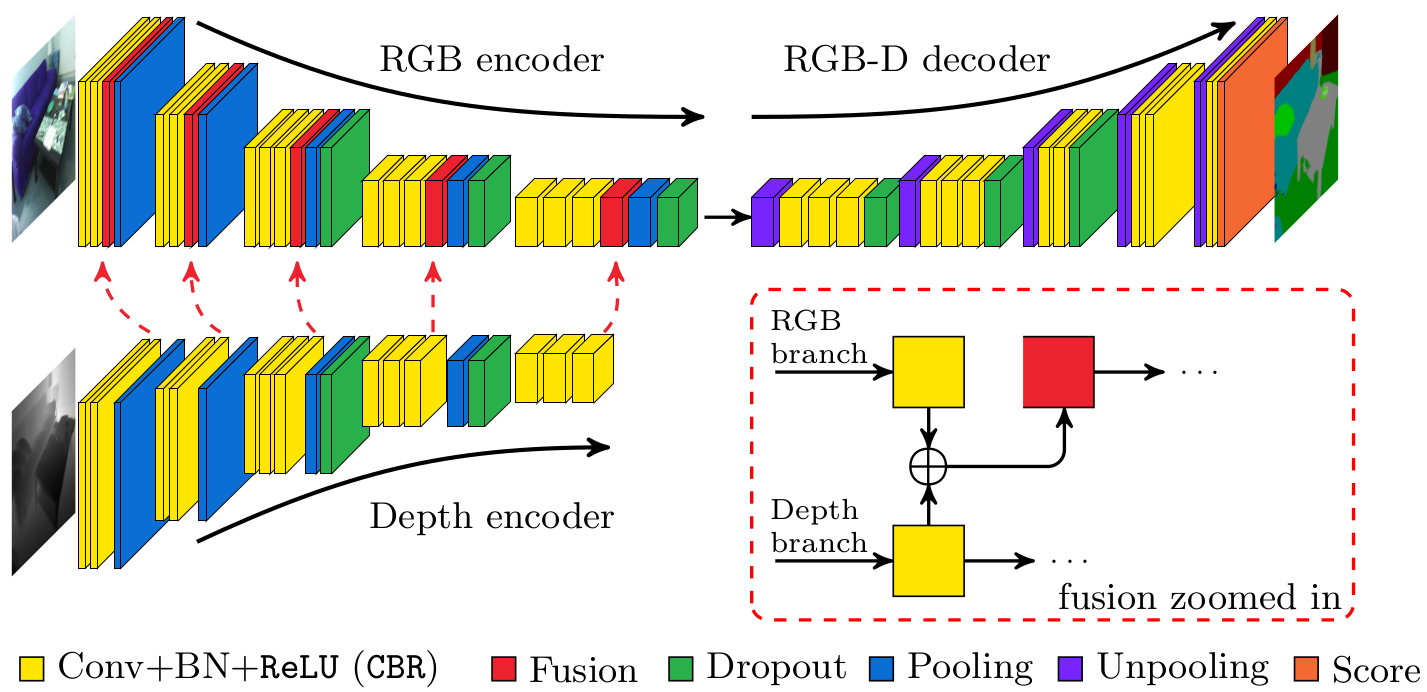
In this paper we address the problem of semantic labeling of indoor scenes on RGB-D data. With the availability of RGB-D cameras, it is expected that additional depth measurement will improve the accuracy. Here we investigate a solution how to incorporate complementary depth information into a semantic segmentation framework by making use of convolutional neural networks (CNNs). Recently encoder-decoder type fully convolutional CNN architectures have achieved a great success in the field of semantic segmentation. Motivated by this observation we propose an encoder-decoder type network, where the encoder part is composed of two branches of networks that simultaneously extract features from RGB and depth images and fuse depth features into the RGB feature maps as the network goes deeper. Comprehensive experimental evaluations demonstrate that the proposed fusion-based architecture achieves competitive results with the state-of-the-art methods on the challenging SUN RGB-D benchmark obtaining 76.27% global accuracy, 48.30% average class accuracy and 37.29% average intersection-over-union score.
† Authors contributed equally.
Bibtex
@inproceedings{hazirbas16fusenet,
title = {FuseNet: Incorporating Depth into Semantic Segmentation via Fusion-based CNN Architecture},
author = {C. Hazirbas and L. Ma and C. Domokos and D. Cremers},
booktitle = {Asian Conference on Computer Vision (ACCV)},
month = {November},
year = {2016},
}